

Firms that want on-line transactions can’t afford server breakdowns. Consequently, these companies search methods to create a failsafe process that retains their information protected even when the server collapses. One such technique is failover clustering.
Failover clustering will be ruled by managed area title system (DNS) supplier options; nonetheless, understanding its mechanism and key options will help restrict any failover challenges.
What’s failover clustering?
Failover clustering is a high-availability answer the place a number of servers work collectively to make sure steady service. If one server fails, one other mechanically takes over. This setup minimizes downtime for purposes, databases, or providers through the use of shared sources and fixed well being monitoring.
This strategy retains your server workloads scalable and accessible. Many main server applications, corresponding to Microsoft Change, Microsoft SQL Server, and Hyper-V, depend on failover clustering to guard themselves.
Some failover clusters make use of bodily servers, whereas others use digital machines (VMs). Everybody selects the form of cluster they want based mostly on the necessities of their server software.
A cluster consists of two or extra nodes that trade information and software program to be processed by means of bodily cables or a specialised safe community. Clustering expertise of a number of sorts can be utilized for load balancing, storage, and concurrent or parallel computing. In some situations, failover clusters are mixed with further clustering applied sciences.
A failover cluster’s main operate is to offer steady availability (CA) or HA for purposes and providers. CA clusters, also referred to as failure-tolerant (FT) clusters, let end-users proceed utilizing purposes and providers even when a server fails. You may see a short interruption in service brought on by HA clusters, however the system can get well with no information loss and little downtime.
TL;DR: All the pieces it is advisable to find out about failover clustering
- What’s failover clustering in easy phrases? It’s a system the place a number of servers work collectively in order that if one fails, one other instantly takes over, protecting purposes on-line with out consumer disruption.
- How does a failover cluster preserve uptime? Servers are linked by means of a non-public “heartbeat” connection that consistently checks for failures. If one server goes down, one other mechanically assumes its workload.
- What’s the distinction between excessive availability and steady availability? HA goals for 99.999% uptime and permits minimal downtime, whereas CA eliminates downtime utterly by means of full redundancy. CA programs are usually extra complicated and dear.
- Why do companies depend on failover clustering? It reduces downtime, helps mission-critical purposes like databases and transactions, and permits fast restoration throughout {hardware} or community failures.
- Does failover clustering work with DNS? Sure, particularly when mixed with a managed DNS supplier, which helps reroute site visitors throughout outages to make sure uninterrupted service supply.
Failover clustering vs. load balancing: What’s the distinction?
Failover clustering and cargo balancing are sometimes used collectively in IT infrastructure, however they serve basically totally different functions.
| Facet | Failover Clustering | Load Balancing |
| Main objective | Redundancy and excessive availability | Efficiency optimization and site visitors distribution |
| Core operate | Mechanically shifts workloads to a standby node when a failure happens | Distributes site visitors or processing evenly throughout a number of lively nodes |
| Node setup | Sometimes active-passive | Sometimes active-active |
| Ideally suited use case | Mission-critical purposes the place downtime impacts information, income, or buyer belief | Functions or providers that have to deal with excessive site visitors and preserve responsiveness |
| Key profit | Retains providers alive throughout failures with minimal disruption | Prevents any single node from turning into overwhelmed and optimizes useful resource utilization |
| Frequent deployment | Used to make sure uptime and information integrity | Typically positioned in entrance of failover clusters for balanced efficiency and resilience |
Put merely, failover clustering retains providers working when failures happen, whereas load balancing retains them working effectively underneath heavy load. In lots of fashionable architectures, each are mixed: load balancing sits in entrance of a failover cluster to ship each uptime safety and useful resource optimization.
Why is failover clustering vital?
With failover clustering, you possibly can restore inactive nodes with out shutting down your database, avoiding downtime issues whereas shortly repairing damaged servers. Moreover, within the occasion of a {hardware} failure, this method terminates the database to guard the lively nodes.
Failover clustering additionally automates information restoration within the occasion of a failure. This reduces your reliance on the info expertise (IT) crew and permits your servers to get well shortly. It additionally delivers glorious structured question language (SQL) cluster availability with minimal downtime. The automated failover performance of failover clustering preserves the operate of your database, even when there’s a {hardware} breakdown.
How do failover clusters work?
Failover clustering consists of two basic processes, HA and CA, for server purposes.
Whereas CA failover clusters attempt to attain 100% availability, HA clusters attempt for 99.999%, generally often called 5 nines. This downtime totals not more than 5.26 minutes every year. CA clusters have increased availability however require extra {hardware} to function, growing their total price.
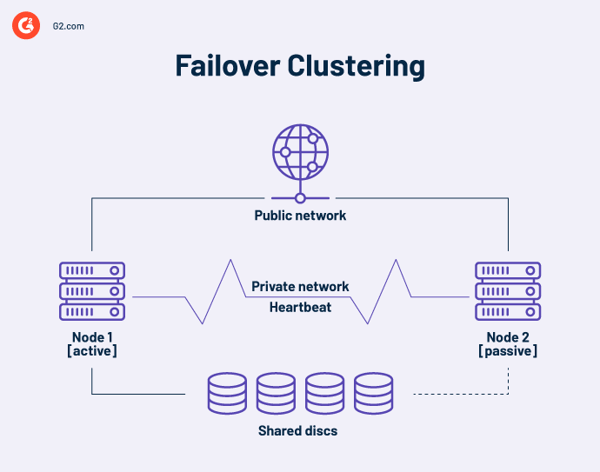
Excessive availability failover clusters
A excessive availability cluster is a set of impartial computer systems that share sources and information. A failover cluster’s nodes have entry to shared storage. A monitoring hyperlink can also be included in high-availability clusters to verify the opposite servers’ heartbeat or well being. A heartbeat is a non-public community shared solely by the nodes within the cluster. It’s not accessible from the skin.
At any level, not less than one node in a cluster is lively, and not less than one is dormant or passive.
In a fundamental two-node association, if Node 1 fails, Node 2 acknowledges the failure through the heartbeat connection and configures itself because the lively node. Clustering software program on every node ensures that purchasers connect with an lively node.
Bigger installations might make use of devoted servers to manage the cluster. A cluster administration server at all times sends heartbeat indicators to establish failing nodes and, in that case, inform one other node to take over the work.
Some cluster administration software program instruments deal with HA for VMs by grouping the machines and servers right into a cluster. If a number fails, a unique host resumes the VMs.
Shared storage represents a threat as a potential single failure level. Nevertheless, combining a redundant array of impartial disks 6 and 10 — aka RAID 6 and RAID 10 — will help preserve service even when two laborious drives fail.
Electrical energy is likely to be one other single level of failure if all servers are related to the identical grid. Offering every node with its personal uninterruptible energy provide (UPS) retains them protected.
Steady availability of failover clusters
In contrast to the HA paradigm, a fault-tolerant cluster contains quite a few computer systems that share a single copy of a pc’s working system (OS). Software program instructions given to at least one system are additionally executed on the opposite programs.
CA insists that the group employs formatted laptop gear and a backup UPS. CA wants a consistently accessible and nearly good duplicate of the bodily or digital system working the service. This redundancy mannequin is named 2N.
CA programs can compensate for a variety of faults. A fault-tolerant system might establish a malfunction of:
- A tough disk drive
- A processing unit in a pc
- A subsystem for enter and output (I/O)
- An influence supply
- A element of a community
The failure level could also be found promptly, and a backup element or technique can take its place instantly with out disrupting the subsequent service.
Clustering software program can join two or extra servers to behave as a single digital server or assemble numerous different CA failover cluster configurations. For example, if one of many digital servers fails, the others reply by briefly eradicating it from the cluster quorum. The digital server then redistributes the burden throughout the opposite servers till the crashed server is able to restart.
A double {hardware} server with all bodily elements replicated is a substitute for CA failover clusters. They compute individually and concurrently on numerous {hardware} platforms and synchronize utilizing a devoted node that screens the outcomes from each bodily servers. Whereas this answer supplies safety, it could be costlier.
Excessive availability clustering vs. steady availability clustering
HA and CA clustering each intention to maintain providers working with minimal disruption, however they differ considerably of their tolerance for downtime and infrastructure complexity. For instance, an e-commerce firm may tolerate 5 minutes of downtime yearly with an HA cluster. However a real-time buying and selling platform? It will possibly’t afford even a second, which is the place CA clusters shine.
HA clusters are designed for near-perfect uptime, usually focusing on 99.999% availability, generally often called “5 nines”, which equates to only over 5 minutes of allowable downtime per yr. These setups use redundant nodes and shared storage to detect failures and shortly change workloads. Nevertheless, a short interruption should happen throughout the failover course of.
CA clusters, in distinction, are constructed for zero downtime. Even when a element fails, be it a CPU, energy provide, or a whole server, the appliance retains working with out lacking a beat. That is achieved by means of synchronized, parallel programs that execute the identical operations concurrently, usually requiring mirrored {hardware} and much more intricate orchestration.
In brief:
- HA is about speedy restoration
- CA is about uninterrupted continuity
Each enhance system resilience, however CA usually calls for increased funding and architectural complexity.
What are the several types of failover clusters?
Important developments in failover clustering have occurred within the final decade, with many organizations now providing their very own model of clustering options. A few of the most typical cluster providers are detailed right here.
VMware failover clusters
VMware supplies quite a few virtualization applied sciences for VM clusters. The vSphere vMotion’s CA structure exactly duplicates a VMware digital machine and its community between bodily information middle networks.
VMware vSphere HA, a second product, supplies HA for VMs by grouping them and their hosts right into a cluster for automated failover. Moreover, this system doesn’t depend on exterior elements corresponding to DNS, which lowers potential factors of failure.
Home windows Server failover cluster
The Home windows Server Failover Cluster (WSFC) technique fosters the creation of Hyper-V failover servers. Between 2016 and 2019, this technique grew well-liked amongst Microsoft Home windows customers. WSFC permits cluster monitoring and affords the mandatory failover mechanism mechanically. Within the occasion of a server loss, WFSC strikes the clusters to a separate node or makes an attempt to restart them. Moreover, its CSV expertise supplies a distributed namespace that permits a number of nodes to share reminiscence.
SQL server
This Microsoft product, launched with SQL Server 2017, has strong HA options that use WSFC expertise. SQL Server elements are thought-about WSFC cluster sources on this context. They’re additional built-in with different WSFC-dependent sources. Consequently, WSFC has authority over figuring out and speaking orders to restart a SQL server occasion or to maneuver situations like these to a brand new node.
Purple Hat Linux
Aside from Microsoft, different working system distributors include their very own failover cluster options. For instance, Purple Hat Enterprise Linux (RHEL) followers can use the HA extension and Purple Hat World File System (GFS/GFS2) to determine HA failover clusters. Single-cluster stretch clusters spanning many places and multi-site, disaster-tolerant clusters are supported. Storage space community (SAN) information storage replication is usually utilized in multi-site clusters.
What are the principle purposes of failover clustering?
This strong mechanism facilitates the next real-time purposes.
Availability of mission-critical purposes.
On-line transaction processing (OLTP) computer systems should have fault-resistant programs. OLTP, which requires full availability, is used for airline reservation programs, digital inventory buying and selling, and ATM banking.
Many industries, corresponding to manufacturing, delivery, and retail, make use of CA clusters or failure-resistant computer systems for mission-critical purposes. E-commerce, order administration, and employees time clock programs depend as examples.
Excessive availability clusters are sometimes acceptable for clustering purposes and providers that require solely five-nines uptime.
Catastrophe aid
Catastrophe restoration additionally advantages from failover clustering. It’s strongly beneficial that failover servers be hosted at distant websites as a result of a calamity corresponding to a hearth or flood destroys all bodily {hardware} and software program.
Storage Reproduction, a expertise that duplicates volumes between servers for catastrophe restoration, is included in Home windows Server 2016 and 2019. Stretch failover is a expertise characteristic that lets failover clusters span two places.
Extending failover clusters permits organizations to replicate information throughout numerous facilities. If tragedy strikes at one location, all information is preserved on failover servers on the others.
Replication of a database
In accordance with Microsoft, the WSFC was first launched in Home windows Server 2016 to safeguard “mission-critical” providers, like its SQL server database and Microsoft Change communications server.
Different distributors provide failover cluster expertise for database replication. For instance, MySQL Cluster has a heartbeat technique that allows quick failure detection to different nodes within the cluster, usually in underneath a literal second, with no service disruptions to purchasers.
Databases could also be replicated to faraway websites utilizing the geographic replication functionality.
How one can implement a failover cluster
Implementing a failover cluster is a structured course of that requires the best {hardware}, software program, and orchestration to make sure seamless availability. Whether or not you are deploying in a conventional information middle or a hybrid cloud setting, these key steps will allow you to construct a resilient, high-availability system.
1. Assess your infrastructure wants
Begin by figuring out the mission-critical workloads you wish to shield. Is that this for SQL Server? Digital machines? File shares? Your supposed use case will affect what number of nodes you want, what sort of shared storage to implement (e.g., SAN, cluster shared volumes (CSV), or cloud-based disks), and whether or not your cluster requires HA or CA.
Additionally, ensure that:
- Every node is working the similar OS model and has the identical software program updates
- Community interfaces are redundant and segregated for manufacturing, heartbeat, and storage site visitors
- Energy sources are remoted per node (use impartial UPS setups to keep away from single factors of failure)
2. Set up required roles and options
On every node (server), set up the mandatory failover clustering elements. In Home windows Server environments:
- Use Server Supervisor or PowerShell to put in the Failover Clustering characteristic
- Embody any wanted providers, like .NET Framework, Hyper-V, or File Server roles, relying in your workload
For Linux-based clusters, set up the suitable cluster stack (e.g., Corosync and Pacemaker on Purple Hat or Debian distributions).
3. Validate your configuration
Run a cluster validation device (e.g., the Cluster Validation Wizard in Home windows Server) to confirm that your nodes are configured appropriately. This device checks:
- Disk configuration and compatibility
- Community connectivity and redundancy
- System settings like time sync, DNS decision, and node communication
Solely proceed if the cluster passes all required validation checks.
4. Create the failover cluster
Use your cluster administration interface (like Failover Cluster Supervisor in Home windows) to create the cluster:
- Choose nodes to incorporate
- Assign a cluster title and static IP deal with
- Select the quorum mannequin (node majority, disk witness, or file share witness) based mostly in your setting and fault tolerance objectives
After creation, check that the cluster is acknowledged and operational.
5. Configure workloads (cluster roles)
Add workloads that ought to be extremely accessible, corresponding to:
- SQL Server situations
- Hyper-V digital machines
- File servers or DFS namespaces
Every workload turns into a cluster position and ought to be configured with startup insurance policies, most well-liked house owners (nodes), and failover precedence.
6. Take a look at failover situations
Manually simulate failures to substantiate your setup works. For instance:
- Energy off one node to see if workloads shift to a different
- Disconnect shared storage or heartbeat hyperlinks
- Verify occasion logs and cluster studies for any missed indicators or delays
If configured correctly, the cluster ought to fail over mechanically with minimal or no consumer influence.
7. Arrange monitoring and automation
Combine your cluster with monitoring programs like System Heart, Zabbix, or Nagios to provide you with a warning when nodes fail, sources transfer, or disk efficiency degrades. It’s also possible to:
- Use PowerShell scripts for automated well being checks
- Implement e-mail or webhook alerts for node failures or quorum loss
Monitoring is essential for proactive upkeep and long-term reliability.
8. Improve with managed DNS
For external-facing providers, combine a managed DNS supplier that may route customers to the right cluster node or web site, even when a node fails or a area goes offline. Suppliers like Cloudflare DNS and Azure DNS provide well being check-based site visitors steering that enhances your failover setup.
What are the advantages of failover clusters?
The thought of failover clusters is to make sure that customers expertise minimal service disruptions. Nevertheless, different further advantages of failover clustering are mentioned under.
- Elevated useful resource availability: If one clever server fails, the others within the cluster choose up the burden, saving essential time and knowledge.
- Strategic useful resource allocation: You get to distribute tasks between nodes in no matter manner you select. This minimizes overhead since not all computer systems are required to execute all tasks concurrently, supplying you with a manner to make use of your sources extra freely.
- Elevated processing energy: Extra machines, extra energy.
- Better scalability: As your consumer base and report complexity broaden, so can your sources.
- Simplified administration: Clustering makes dealing with important or shortly altering programs simpler.
What are the restrictions of failover clustering?
As important as failover clustering is, it comes up towards the next limitations.
- Advanced configurations: A failover clustering configuration for Home windows requires dealing with many networks and community playing cards directly. Deploying this technique is troublesome, particularly for freshmen.
- Software integrations: Home windows failover clustering and Hyper-V should be extra intently built-in. You need to alter every to finish failover clustering efficiently.
- Net interface: There’s no net interface to regulate cluster parameters. To entry the cluster supervisor characteristic, you could manually log in to a distant desktop.
High 5 managed DNS suppliers:
Selecting a dependable managed DNS supplier is important for making certain quick, safe, and resilient community efficiency, particularly as uptime and world attain change into non-negotiables for digital companies.
Primarily based on G2’s Summer time 2025 Grid® Report, the next are the top-rated managed DNS software program options, ranked by verified consumer evaluations and market presence:

{kind=link}
Failover clustering: Steadily requested questions
Q. How does a failover cluster detect a failure?
Clusters use a heartbeat mechanism, a devoted communication channel that constantly checks every node’s standing. If a node stops responding, the system detects the failure and initiates a failover course of to reroute workloads.
Q. Can I take advantage of failover clustering with digital machines?
Sure. Platforms like VMware vSphere and Microsoft Hyper-V help failover clustering for digital machines. If a number server fails, the cluster mechanically strikes VMs to a different wholesome node to maintain providers working with out handbook intervention.
Q. Do I would like shared storage for a failover cluster?
In most conventional failover cluster setups, shared storage is required to provide all nodes entry to the identical information and software information. That is usually managed utilizing applied sciences like SAN, NAS, or Cluster Shared Volumes. Some fashionable programs use information replication to keep away from a single level of failure in storage.
Q. Can DNS assist throughout a failover occasion?
Sure. Managed DNS providers can monitor server well being and mechanically redirect site visitors to backup nodes or information facilities throughout an outage. This enhances the effectiveness of your failover system by making certain customers are at all times routed to a functioning endpoint.
Q. What industries rely most on failover clustering?
Industries that require fixed uptime rely closely on failover clustering. These embody monetary providers, healthcare, manufacturing, telecommunications, authorities, and e-commerce sectors, the place even transient downtime can have severe penalties.
Modernizing reliability
Failover clustering has emerged as a dependable and important choice for prime availability and fault tolerance inside present IT infrastructures. It supplies ongoing operations regardless of {hardware} failures or scheduled upkeep by mechanically spreading workloads and sources throughout quite a few networked nodes. This expertise offers you one other technique to deal with a very powerful side of your small business – making every buyer’s expertise protected and completely happy.
Fortifying your system’s resilience doesn’t harm, both!
Get began with a information to DNS safety for a strong system technique.
This text was initially revealed in 2023. It has been up to date with new info.