

{kind=link}
The not too long ago launched DeepSeek-R1 mannequin household has introduced a brand new wave of pleasure to the AI neighborhood, permitting fanatics and builders to run state-of-the-art reasoning fashions with problem-solving, math and code capabilities, all from the privateness of native PCs.
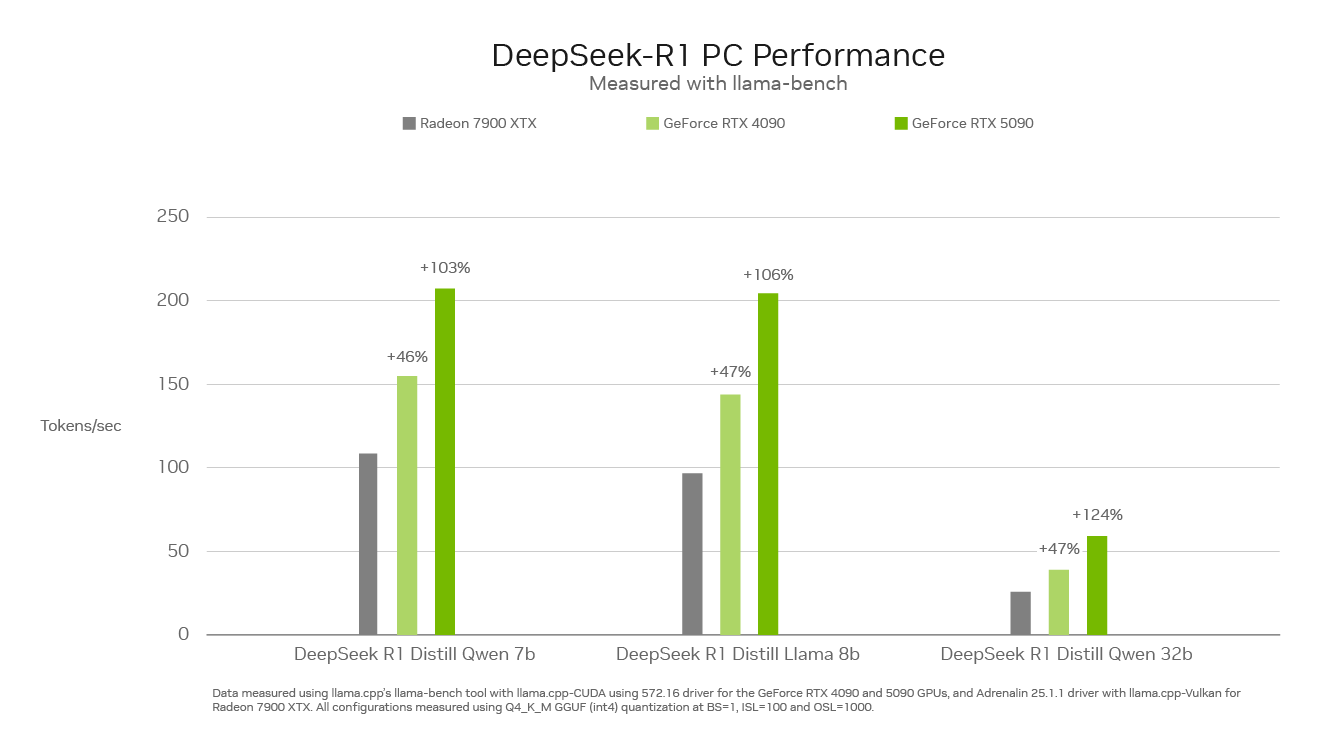
With as much as 3,352 trillion operations per second of AI horsepower, NVIDIA GeForce RTX 50 Collection GPUs can run the DeepSeek household of distilled fashions quicker than something on the PC market.
A New Class of Fashions That Cause
Reasoning fashions are a brand new class of huge language fashions (LLMs) that spend extra time on “pondering” and “reflecting” to work via complicated issues, whereas describing the steps required to unravel a activity.
The basic precept is that any drawback may be solved with deep thought, reasoning and time, identical to how people deal with issues. By spending extra time — and thus compute — on an issue, the LLM can yield higher outcomes. This phenomenon is named test-time scaling, the place a mannequin dynamically allocates compute assets throughout inference to motive via issues.
Reasoning fashions can improve consumer experiences on PCs by deeply understanding a consumer’s wants, taking actions on their behalf and permitting them to offer suggestions on the mannequin’s thought course of — unlocking agentic workflows for fixing complicated, multi-step duties resembling analyzing market analysis, performing difficult math issues, debugging code and extra.
The DeepSeek Distinction
The DeepSeek-R1 household of distilled fashions relies on a big 671-billion-parameter mixture-of-experts (MoE) mannequin. MoE fashions include a number of smaller professional fashions for fixing complicated issues. DeepSeek fashions additional divide the work and assign subtasks to smaller units of consultants.
DeepSeek employed a method known as distillation to construct a household of six smaller scholar fashions — starting from 1.5-70 billion parameters — from the massive DeepSeek 671-billion-parameter mannequin. The reasoning capabilities of the bigger DeepSeek-R1 671-billion-parameter mannequin have been taught to the smaller Llama and Qwen scholar fashions, leading to highly effective, smaller reasoning fashions that run regionally on RTX AI PCs with quick efficiency.
Peak Efficiency on RTX
Inference velocity is vital for this new class of reasoning fashions. GeForce RTX 50 Collection GPUs, constructed with devoted fifth-generation Tensor Cores, are primarily based on the identical NVIDIA Blackwell GPU structure that fuels world-leading AI innovation within the information heart. RTX totally accelerates DeepSeek, providing most inference efficiency on PCs.
Expertise DeepSeek on RTX in Well-liked Instruments
NVIDIA’s RTX AI platform provides the broadest collection of AI instruments, software program growth kits and fashions, opening entry to the capabilities of DeepSeek-R1 on over 100 million NVIDIA RTX AI PCs worldwide, together with these powered by GeForce RTX 50 Collection GPUs.
Excessive-performance RTX GPUs make AI capabilities all the time obtainable — even with out an web connection — and provide low latency and elevated privateness as a result of customers don’t must add delicate supplies or expose their queries to an internet service.
Expertise the ability of DeepSeek-R1 and RTX AI PCs via an enormous ecosystem of software program, together with Llama.cpp, Ollama, LM Studio, AnythingLLM, Jan.AI, GPT4All and OpenWebUI, for inference. Plus, use Unsloth to fine-tune the fashions with customized information.