

{kind=link}
Coding assistants or copilots — AI-powered assistants that may recommend, clarify and debug code — are essentially altering how software program is developed for each skilled and novice builders.
Skilled builders use these assistants to remain targeted on advanced coding duties, scale back repetitive work and discover new concepts extra shortly. Newer coders — like college students and AI hobbyists — profit from coding assistants that speed up studying by describing totally different implementation approaches or explaining what a bit of code is doing and why.
Coding assistants can run in cloud environments or regionally. Cloud-based coding assistants might be run anyplace however provide some limitations and require a subscription. Native coding assistants take away these points however require performant {hardware} to function nicely.
NVIDIA GeForce RTX GPUs present the mandatory {hardware} acceleration to run native assistants successfully.
Code, Meet Generative AI
Conventional software program growth consists of many mundane duties akin to reviewing documentation, researching examples, organising boilerplate code, authoring code with acceptable syntax, tracing down bugs and documenting capabilities. These are important duties that may take time away from downside fixing and software program design. Coding assistants assist streamline such steps.
Many AI assistants are linked with well-liked built-in growth environments (IDEs) like Microsoft Visible Studio Code or JetBrains’ Pycharm, which embed AI help straight into current workflows.
There are two methods to run coding assistants: within the cloud or regionally.
Cloud-based coding assistants require supply code to be despatched to exterior servers earlier than responses are returned. This strategy might be laggy and impose utilization limits. Some builders desire to maintain their code native, particularly when working with delicate or proprietary tasks. Plus, many cloud-based assistants require a paid subscription to unlock full performance, which generally is a barrier for college students, hobbyists and groups that must handle prices.
Coding assistants run in a neighborhood setting, enabling cost-free entry with:
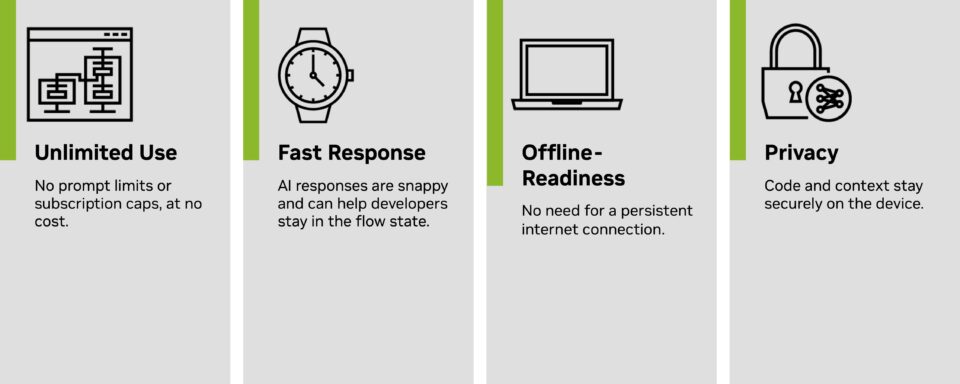
Get Began With Native Coding Assistants
Instruments that make it straightforward to run coding assistants regionally embrace:
- Proceed.dev — An open-source extension for the VS Code IDE that connects to native massive language fashions (LLMs) by way of Ollama, LM Studio or customized endpoints. This device affords in-editor chat, autocomplete and debugging help with minimal setup. Get began with Proceed.dev utilizing the Ollama backend for native RTX acceleration.
- Tabby — A safe and clear coding assistant that’s appropriate throughout many IDEs with the power to run AI on NVIDIA RTX GPUs. This device affords code completion, answering queries, inline chat and extra. Get began with Tabby on NVIDIA RTX AI PCs.
- OpenInterpreter — Experimental however quickly evolving interface that mixes LLMs with command-line entry, file modifying and agentic job execution. Excellent for automation and devops-style duties for builders. Get began with OpenInterpreter on NVIDIA RTX AI PCs.
- LM Studio — A graphical consumer interface-based runner for native LLMs that provides chat, context window administration and system prompts. Optimum for testing coding fashions interactively earlier than IDE deployment. Get began with LM Studio on NVIDIA RTX AI PCs.
- Ollama — A neighborhood AI mannequin inferencing engine that allows quick, personal inference of fashions like Code Llama, StarCoder2 and DeepSeek. It integrates seamlessly with instruments like Proceed.dev.
These instruments help fashions served by frameworks like Ollama or llama.cpp, and lots of are actually optimized for GeForce RTX and NVIDIA RTX PRO GPUs.
See AI-Assisted Studying on RTX in Motion
Operating on a GeForce RTX-powered PC, Proceed.dev paired with the Gemma 12B Code LLM helps clarify current code, discover search algorithms and debug points — all completely on system. Appearing like a digital instructing assistant, the assistant supplies plain-language steerage, context-aware explanations, inline feedback and prompt code enhancements tailor-made to the consumer’s mission.
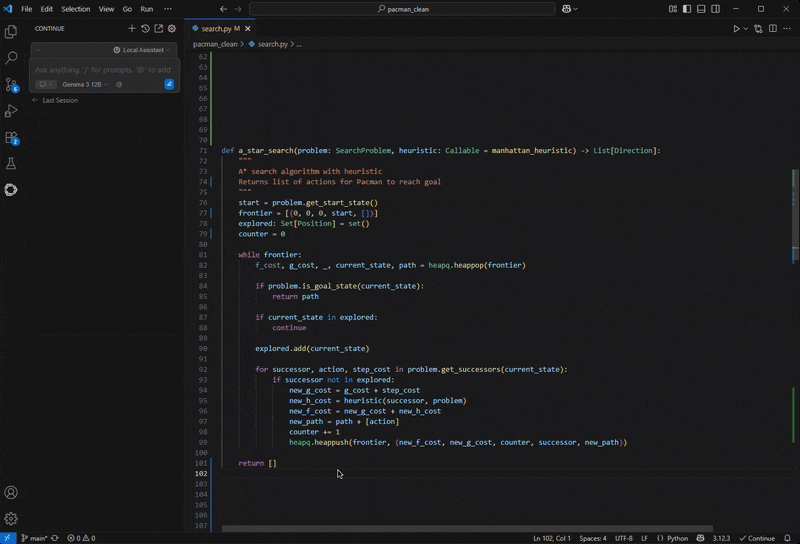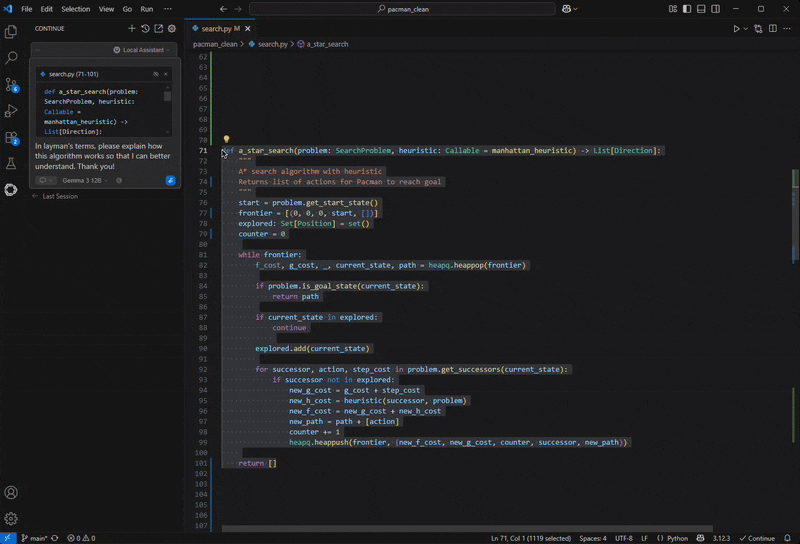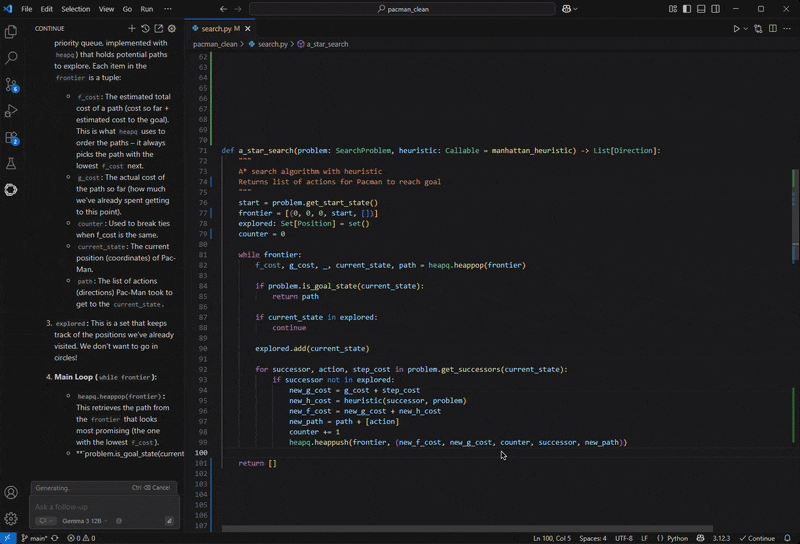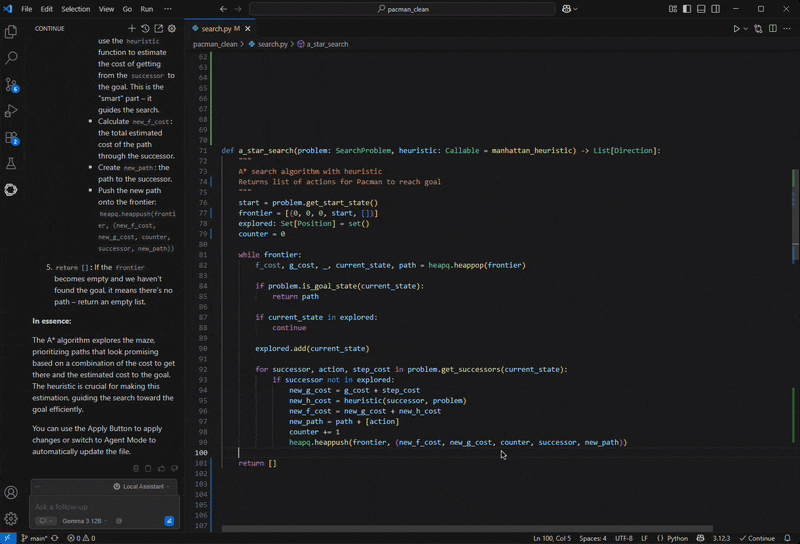
This workflow highlights the benefit of native acceleration: the assistant is all the time out there, responds immediately and supplies customized help, all whereas conserving the code personal on system and making the training expertise immersive.
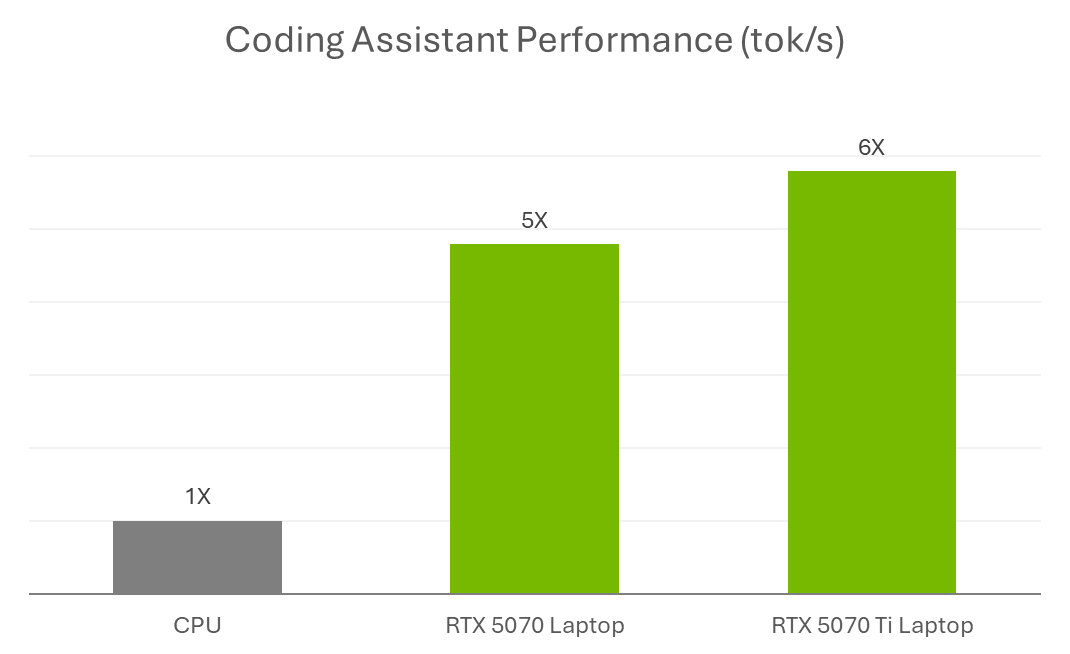
That degree of responsiveness comes right down to GPU acceleration. Fashions like Gemma 12B are compute-heavy, particularly once they’re processing lengthy prompts or working throughout a number of recordsdata. Operating them regionally and not using a GPU can really feel sluggish — even for easy duties. With RTX GPUs, Tensor Cores speed up inference straight on the system, so the assistant is quick, responsive and in a position to sustain with an lively growth workflow.
Whether or not used for educational work, coding bootcamps or private tasks, RTX AI PCs are enabling builders to construct, study and iterate sooner with AI-powered instruments.
For these simply getting began — particularly college students constructing their expertise or experimenting with generative AI — NVIDIA GeForce RTX 50 Sequence laptops function specialised AI applied sciences that speed up high functions for studying, creating and gaming, all on a single system. Discover RTX laptops best for back-to-school season.
And to encourage AI fanatics and builders to experiment with native AI and lengthen the capabilities of their RTX PCs, NVIDIA is internet hosting a Plug and Play: Challenge G-Help Plug-In Hackathon — working nearly by Wednesday, July 16. Individuals can create customized plug-ins for Challenge G-Help, an experimental AI assistant designed to answer pure language and lengthen throughout inventive and growth instruments. It’s an opportunity to win prizes and showcase what’s doable with RTX AI PCs.
Be part of NVIDIA’s Discord server to attach with neighborhood builders and AI fanatics for discussions on what’s doable with RTX AI.
Every week, the RTX AI Storage weblog sequence options community-driven AI improvements and content material for these seeking to study extra about NVIDIA NIM microservices and AI Blueprints, in addition to constructing AI brokers, inventive workflows, digital people, productiveness apps and extra on AI PCs and workstations.
Plug in to NVIDIA AI PC on Fb, Instagram, TikTok and X — and keep knowledgeable by subscribing to the RTX AI PC e-newsletter.
Observe NVIDIA Workstation on LinkedIn and X.
See discover concerning software program product info.