

{kind=link}
Giant language fashions (LLMs), skilled on datasets with billions of tokens, can generate high-quality content material. They’re the spine for most of the hottest AI functions, together with chatbots, assistants, code mills and far more.
Considered one of immediately’s most accessible methods to work with LLMs is with AnythingLLM, a desktop app constructed for lovers who need an all-in-one, privacy-focused AI assistant straight on their PC.
With new assist for NVIDIA NIM microservices on NVIDIA GeForce RTX and NVIDIA RTX PRO GPUs, AnythingLLM customers can now get even quicker efficiency for extra responsive native AI workflows.
What Is AnythingLLM?
AnythingLLM is an all-in-one AI utility that lets customers run native LLMs, retrieval-augmented era (RAG) programs and agentic instruments.
It acts as a bridge between a consumer’s most popular LLMs and their information, and allows entry to instruments (known as expertise), making it simpler and extra environment friendly to make use of LLMs for particular duties like:
- Query answering: Getting solutions to questions from high LLMs — like Llama and DeepSeek R1 — with out incurring prices.
- Private information queries: Use RAG to question content material privately, together with PDFs, Phrase recordsdata, codebases and extra.
- Doc summarization: Producing summaries of prolonged paperwork, like analysis papers.
- Knowledge evaluation: Extracting information insights by loading recordsdata and querying it with LLMs.
- Agentic actions: Dynamically researching content material utilizing native or distant sources, operating generative instruments and actions primarily based on consumer prompts.
AnythingLLM can hook up with all kinds of open-source native LLMs, in addition to bigger LLMs within the cloud, together with these offered by OpenAI, Microsoft and Anthropic. As well as, the appliance gives entry to expertise for extending its agentic AI capabilities through its group hub.
With a one-click set up and the flexibility to launch as a standalone app or browser extension — wrapped in an intuitive expertise with no sophisticated setup required — AnythingLLM is a superb choice for AI lovers, particularly these with GeForce RTX and NVIDIA RTX PRO GPU-equipped programs.
RTX Powers AnythingLLM Acceleration
GeForce RTX and NVIDIA RTX PRO GPUs supply important efficiency positive aspects for operating LLMs and brokers in AnythingLLM — rushing up inference with Tensor Cores designed to speed up AI.
AnythingLLM runs LLMs with Ollama for on-device execution accelerated by Llama.cpp and ggml tensor libraries for machine studying.
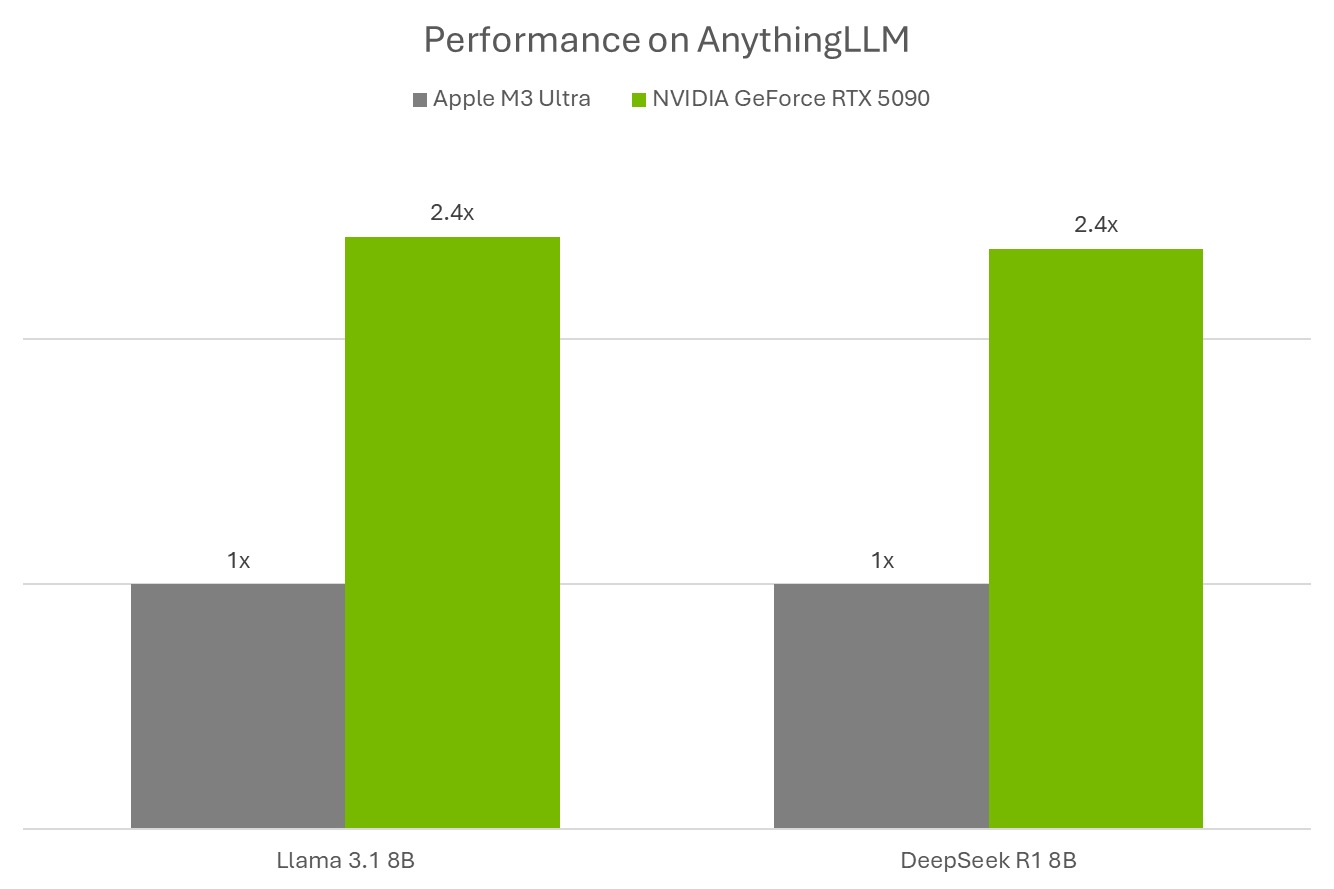
Ollama, Llama.cpp and GGML are optimized for NVIDIA RTX GPUs and the fifth-generation Tensor Cores. Efficiency on GeForce RTX 5090 is 2.4X in comparison with an Apple M3 Extremely.
As NVIDIA provides new NIM microservices and reference workflows — like its rising library of AI Blueprints — instruments like AnythingLLM will unlock much more multimodal AI use circumstances.
AnythingLLM — Now With NVIDIA NIM
AnythingLLM lately added assist for NVIDIA NIM microservices — performance-optimized, prepackaged generative AI fashions that make it straightforward to get began with AI workflows on RTX AI PCs with a streamlined API.
NVIDIA NIMs are nice for builders searching for a fast option to take a look at a Generative AI mannequin in a workflow. As an alternative of getting to search out the fitting mannequin, obtain all of the recordsdata and determine find out how to join all the things, they supply a single container that has all the things you want. And so they can run each on Cloud and PC, making it straightforward to prototype regionally after which deploy on the cloud.
By providing them inside AnythingLLM’s user-friendly UI, customers have a fast option to take a look at them and experiment with them. After which they’ll both join them to their workflows with AnythingLLM, or leverage NVIDIA AI Blueprints and NIM documentation and pattern code to plug them on to their apps or tasks.
Discover the big variety of NIM microservices out there to raise AI-powered workflows, together with language and picture era, pc imaginative and prescient and speech processing.
Every week, the RTX AI Storage weblog collection options community-driven AI improvements and content material for these seeking to be taught extra about NIM microservices and AI Blueprints, in addition to constructing AI brokers, inventive workflows, digital people, productiveness apps and extra on AI PCs and workstations.
Plug in to NVIDIA AI PC on Fb, Instagram, TikTok and X — and keep knowledgeable by subscribing to the RTX AI PC e-newsletter.
Observe NVIDIA Workstation on LinkedIn and X. See discover relating to software program product info.